library(Hmisc)
library(survival)
library(rms)
library(scales)
library(ggplot2)
library(latex2exp)
library(knitr)
library(kableExtra)
library(modelsummary)
getHdata(prostate)Cox model case study
R
Survival analysis
Analyzing prostate cancer dataset using a Cox model. The primary goal is to discover patterns in survival, and to do an analysis of covariance to assess the effect of treatment while adjusting for patient heterogeneity. Prediction is a secondary goal.
Data
We consider the 506-patient prostate cancer dataset from Byar and Green. These data were from a randomized trial comparing four treatments for stage 3 and 4 prostate cancer, with almost equal numbers of patients on placebo and each of three doses of estrogen. Four patients had missing values on all of the following variables: wt, pf, hx, sbp, dbp, ekg, hg, bm; two of these patients were also missing sz. These patients are excluded from consideration.
We will follow guidelines given in the book Regression Modeling Strategies by Frank Harrell and his general approach to this dataset in Chapter 21. The analysis is expanded compared to what was done in the book.
There are 354 deaths among the 502 patients and we will use a multivariate survival model to explain the time until death (of any cause).
Loading data
We start by showing summary of all the variables in the dataset
Click here to see output
Preprocess data for function datasummary_skim.
prostate_summary <- prostate
# Convert 'labelled' columns to numeric
prostate_summary[] <- lapply(prostate_summary, function(x) {
if (inherits(x, "labelled")) {
as.numeric(x)
} else {
x
}
})
prostate_summary$bm <- as.factor(prostate$bm)
prostate_summary$stage <- as.factor(prostate$stage)
prostate_summary$hx <- as.factor(prostate$hx)
prostate_summary <- prostate_summary[
,
!names(prostate) %in% c("patno", "sdate")
]
factors <- sapply(prostate_summary, is.factor)Summary of factor variables in data
datasummary_skim(prostate_summary[factors])| N | % | ||
|---|---|---|---|
| stage | 3 | 289 | 57.6 |
| 4 | 213 | 42.4 | |
| rx | placebo | 127 | 25.3 |
| 0.2 mg estrogen | 124 | 24.7 | |
| 1.0 mg estrogen | 126 | 25.1 | |
| 5.0 mg estrogen | 125 | 24.9 | |
| status | alive | 148 | 29.5 |
| dead - prostatic ca | 130 | 25.9 | |
| dead - heart or vascular | 96 | 19.1 | |
| dead - cerebrovascular | 31 | 6.2 | |
| dead - pulmonary embolus | 14 | 2.8 | |
| dead - other ca | 25 | 5.0 | |
| dead - respiratory disease | 16 | 3.2 | |
| dead - other specific non-ca | 28 | 5.6 | |
| dead - unspecified non-ca | 7 | 1.4 | |
| dead - unknown cause | 7 | 1.4 | |
| pf | normal activity | 450 | 89.6 |
| in bed < 50% daytime | 37 | 7.4 | |
| in bed > 50% daytime | 13 | 2.6 | |
| confined to bed | 2 | 0.4 | |
| hx | 0 | 289 | 57.6 |
| 1 | 213 | 42.4 | |
| ekg | normal | 168 | 33.5 |
| benign | 23 | 4.6 | |
| rhythmic disturb & electrolyte ch | 51 | 10.2 | |
| heart block or conduction def | 26 | 5.2 | |
| heart strain | 150 | 29.9 | |
| old MI | 75 | 14.9 | |
| recent MI | 1 | 0.2 | |
| bm | 0 | 420 | 83.7 |
| 1 | 82 | 16.3 |
Summary of continuous variables in data
datasummary_skim(prostate_summary[!factors])| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| dtime | 76 | 0 | 36.1 | 23.3 | 0.0 | 34.0 | 76.0 |  |
| age | 42 | 0 | 71.5 | 7.1 | 48.0 | 73.0 | 89.0 |  |
| wt | 68 | 0 | 99.0 | 13.4 | 69.0 | 98.0 | 152.0 |  |
| sbp | 18 | 0 | 14.4 | 2.4 | 8.0 | 14.0 | 30.0 |  |
| dbp | 12 | 0 | 8.1 | 1.5 | 4.0 | 8.0 | 18.0 |  |
| hg | 91 | 0 | 13.4 | 2.0 | 5.9 | 13.7 | 21.2 |  |
| sz | 56 | 1 | 14.6 | 12.3 | 0.0 | 11.0 | 69.0 |  |
| sg | 12 | 2 | 10.3 | 2.0 | 5.0 | 10.0 | 15.0 |  |
| ap | 128 | 0 | 12.2 | 62.2 | 0.1 | 0.7 | 999.9 |  |
We see that the variable ekg only has one observation in the last category and pf has two. So, we combine recent MI with old MI and call it MI, and we combine confined to bed with \(>50\%\) daytime.
levels(prostate$ekg)[levels(prostate$ekg) %in% c("old MI", "recent MI")] <- "MI"
levels(prostate$pf) <- c(
levels(prostate$pf)[1:3],
levels(prostate$pf)[3]
)Imputing missing values
We have 27 patients with missing values as seen below, so we do imputation on these.
The proportion of missing values is \(0.05\), so we just do single imputation, since simpler to make plots and validation. However if the proportion were higher one should do multiple imputation.
sum(is.na(prostate))[1] 27colSums(is.na(prostate)) patno stage rx dtime status age wt pf hx sbp dbp
0 0 0 0 0 1 2 0 0 0 0
ekg hg sz sg ap bm sdate
8 0 5 11 0 0 0 w <- transcan(
~ sz + sg + ap + sbp + dbp + age +
wt + hg + ekg + pf + bm + hx,
imputed = TRUE,
data = prostate, pl = FALSE, pr = FALSE
)
attach(prostate)
sz <- impute(w, sz, data = prostate)
sg <- impute(w, sg, data = prostate)
age <- impute(w, age, data = prostate)
wt <- impute(w, wt, data = prostate)
kg <- impute(w, ekg, data = prostate)Specifying the model
A Cox proportional hazards model is in terms of the hazard function given by: \[\lambda(t\vert X)=\lambda(t)\exp(X\beta).\] We fit a Cox proportional hazards model with the predictors and their degrees of freedom specified in the table below. All continuous predictors will be modeled with a restricted cubic spline with 4 knots.
| Predictor | Name | d.f. | Levels |
|---|---|---|---|
| Dose of estrogen | rx | 3 | placebo, 0.2, 1.0, 5.0 mg estrogen |
| Age in years | age | 3 | |
| Weight index | wt | 3 | |
| Performance rating | pf | 2 | normal, in bed < 50% of time, in bed > 50% |
| History of cardiovascular disease | hx | 1 | present/absent |
| Systolic blood pressure/10 | sbp | 3 | |
| Diastolic blood pressure/10 | dbp | 3 | |
| Electrocardiogram code | ekg | 5 | normal, benign, rhythm disturb., block, strain, myocardial infarction |
| Serum hemoglobin (g/100ml) | hg | 3 | |
| Tumor size (cm^2) | sz | 3 | |
| Stage/histologic grade combination | sg | 3 | |
| Serum prostatic acid phosphatase | ap | 3 | |
| Bone metastasis | bm | 1 | present/absent |
We see that we have 36 degrees of freedom in our model, so about 1/10 of the amount of deaths there are. So there is some hope our model will validate.
dd <- datadist(prostate)
options(datadist = "dd")
units(prostate$dtime) <- "Month"
s <- Surv(prostate$dtime, prostate$status != "alive")
f <- cph(s ~ rx + rcs(age, 4) + rcs(wt, 4) + pf + hx +
rcs(sbp, 4) + rcs(dbp, 4) + ekg + rcs(hg, 4) +
rcs(sg, 4) + rcs(sz, 4) + rcs(log(ap), 4) + bm, data = prostate)
print(f, html = TRUE, coefs = FALSE)Frequencies of Missing Values Due to Each Variable
s rx age wt pf hx sbp dbp ekg hg sg sz ap bm
0 0 1 2 0 0 0 0 8 0 11 5 0 0
Cox Proportional Hazards Model
cph(formula = s ~ rx + rcs(age, 4) + rcs(wt, 4) + pf + hx + rcs(sbp,
4) + rcs(dbp, 4) + ekg + rcs(hg, 4) + rcs(sg, 4) + rcs(sz,
4) + rcs(log(ap), 4) + bm, data = prostate)
Model Tests Discrimination
Indexes
Obs 475 LR chi2 136.31 R2 0.250
Events 338 d.f. 36 R2(36,475)0.190
Center -1.9598 Pr(> chi2) 0.0000 R2(36,338)0.257
Score chi2 145.22 Dxy 0.344
Pr(> chi2) 0.0000 Test for removing all predictors is highly significant, so modelling is warranted. AIC on the \(\chi^2\)-scale is given by \(136.04-2\cdot 36=64.04\). A rough shrinkage estimate is thus given by \((136.04-36)/136.04=0.74\). So we estimate that 0.26 of the model fitting will be noise, especially with regard to calibration accuracy. One approach would just be to multiply coefficients of final model if used for prediction by the shrinkage estimate. Instead we try to do some data reduction using domain knowledge.
Data reduction using domain knowledge
We do the following changes
Combine systolic blood pressure (sbp) and diastolic blood pressure (dbp) into Mean Arterial Pressure.
Combine history of cardiovascular disease (hx) and electrocardiogram code ekg and assume linear. We code it as 2 if ekg are not normal or benign and hx, 1 if either, and 0 if none.
Weight index not that important, so only use 3 knots.
Take log of Serum prostatic acid phosphatase (ap) for numeric stability (heavy right-tail) and allow 1 more knot for compensation
The tumor variables tumor size (sz) and stage/histologic grade combination (sg) should be important variables, but since we have both we keep them but give them only 3 knots each.
Assume performance rating (pf) is linear.
prostate$map <- (2 * prostate$dbp + prostate$sbp) / 3
label(prostate$map) <- "Mean Arterial Pressure/10"
prostate$heart_d <- prostate$hx + prostate$ekg %nin% c("normal", "benign")
label(prostate$heart_d) <- "Heart Disease Code"
prostate$pf_linear <- as.numeric(prostate$pf)So all in all we save 3 degrees of freedom from defining map, 5 for defining Heart Disease Code, and 3 for dropping knots, 1 for assuming performance rating is linear and gain 1 from ap. For a total reduction of 11 degrees of freedom.
dd <- datadist(prostate)
options(datadist = "dd")
f <- cph(
s ~ rx + rcs(age, 4) + rcs(wt, 3) + pf_linear + heart_d + rcs(map, 3)
+ rcs(hg, 4) + rcs(sg, 3) + rcs(sz, 3) + rcs(log(ap), 5) + bm,
x = TRUE, y = TRUE, surv = TRUE, time.inc = 5 * 12, data = prostate
)
print(f, html = TRUE, coefs = 3)Frequencies of Missing Values Due to Each Variable
s rx age wt pf_linear heart_d map hg
0 0 1 2 0 0 0 0
sg sz ap bm
11 5 0 0
Cox Proportional Hazards Model
cph(formula = s ~ rx + rcs(age, 4) + rcs(wt, 3) + pf_linear +
heart_d + rcs(map, 3) + rcs(hg, 4) + rcs(sg, 3) + rcs(sz,
3) + rcs(log(ap), 5) + bm, data = prostate, x = TRUE, y = TRUE,
surv = TRUE, time.inc = 5 * 12)
Model Tests Discrimination
Indexes
Obs 483 LR chi2 118.48 R2 0.218
Events 344 d.f. 24 R2(24,483)0.178
Center -2.2006 Pr(> chi2) 0.0000 R2(24,344)0.240
Score chi2 125.95 Dxy 0.323
Pr(> chi2) 0.0000
Coef S.E. Wald Z Pr(>|Z|)
rx=0.2 mg estrogen -0.0131 0.1518 -0.09 0.9314
rx=1.0 mg estrogen -0.3867 0.1675 -2.31 0.0210
rx=5.0 mg estrogen -0.0916 0.1595 -0.57 0.5656
. . . LR 119.86 with 24 degrees of freedom. AIC is \(119.86-2 \cdot 24=71.86\). Rough shrinkage estimate of this is now better at \((119.86-24)/119.86=0.80\).
anova(f, html = TRUE) Wald Statistics Response: s
Factor Chi-Square d.f. P
rx 6.61 3 0.0856
age 12.30 3 0.0064
Nonlinear 7.69 2 0.0214
wt 8.48 2 0.0144
Nonlinear 3.39 1 0.0655
pf_linear 3.27 1 0.0706
heart_d 23.90 1 <.0001
map 0.28 2 0.8683
Nonlinear 0.21 1 0.6479
hg 8.89 3 0.0308
Nonlinear 3.95 2 0.1386
sg 2.39 2 0.3031
Nonlinear 0.00 1 0.9974
sz 12.42 2 0.0020
Nonlinear 0.04 1 0.8443
ap 6.95 4 0.1388
Nonlinear 6.77 3 0.0795
bm 0.17 1 0.6772
TOTAL NONLINEAR 20.66 11 0.0371
TOTAL 119.17 24 <.0001We see that the p-value for the treatment, doses of estrogen (rx), is below \(0.05\), so it seems like it has some effect.
Checking Proportional Hazards
A Cox model should have proportional hazards, since if we look at two individuals with covariate values \(\boldsymbol{X}\) and \(\boldsymbol{X}^*\) then the ratio of their hazard rates is \[\frac{h(t \vert \boldsymbol{X})}{h(t \vert \boldsymbol{X}^*)}=\exp\Big[\sum_{k=1}^p \beta_k(X_k-X_{k^*})\Big],\] which is a constant. We can test this assumption using scaled Schoenfeld residuals separately for each predictor and test the PH assumption using the “correlation with time” test. Smoothed trends in the residuals are also plotted.
z <- predict(f, type = "terms", data = prostate)
f_short <- cph(s ~ z, x = TRUE, y = TRUE, data = prostate)
phtest <- cox.zph(f_short, transform = "identity", terms = FALSE)
phtest chisq df p
rx 3.63e+00 1 0.057
age 1.63e+00 1 0.201
wt 1.28e-02 1 0.910
pf_linear 1.15e-02 1 0.915
heart_d 3.58e-01 1 0.550
map 1.61e+00 1 0.205
hg 1.18e-01 1 0.731
sg 1.28e-02 1 0.910
sz 2.38e-05 1 0.996
ap 1.41e-01 1 0.707
bm 2.25e-01 1 0.635
GLOBAL 8.89e+00 11 0.632We see that the p-value of the test for proportional hazards is below \(0.05\) for dose of estrogen, indicating that it may not have constant relative hazard. We plot it and don’t find anything too worry-some, and the global test of proportional hazard by adjusting for the 11 tests gives a p-value of \(0.78\). So we accept our model and continue.
plot(phtest, var = "rx")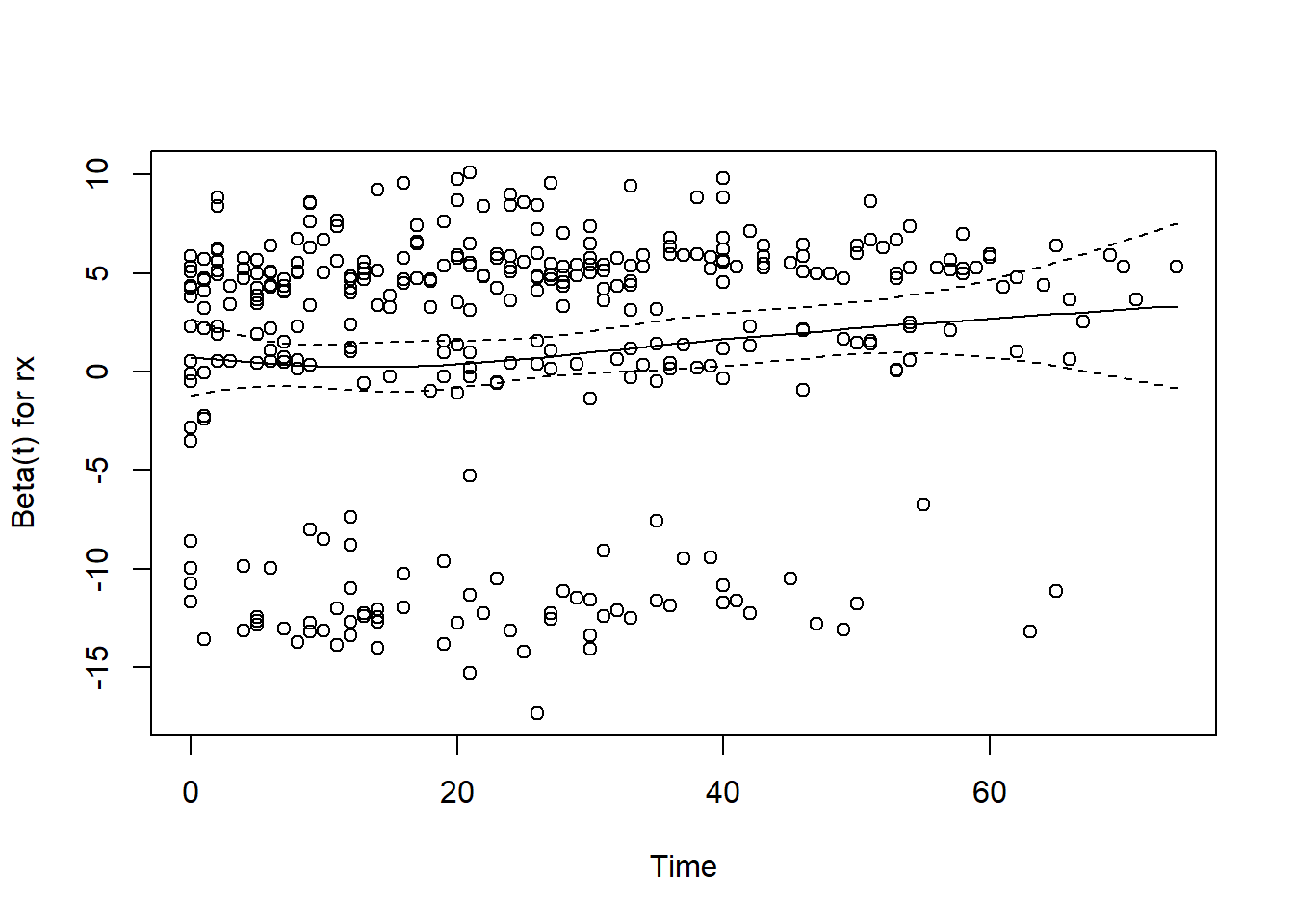
Describing Effects
We plot how each predictor is related to the log hazard of death with \(95\%\)-confidence bands.
ggplot(Predict(f),
sepdiscrete = "vertical", nlevels = 4,
vnames = "names"
)`height` was translated to `width`.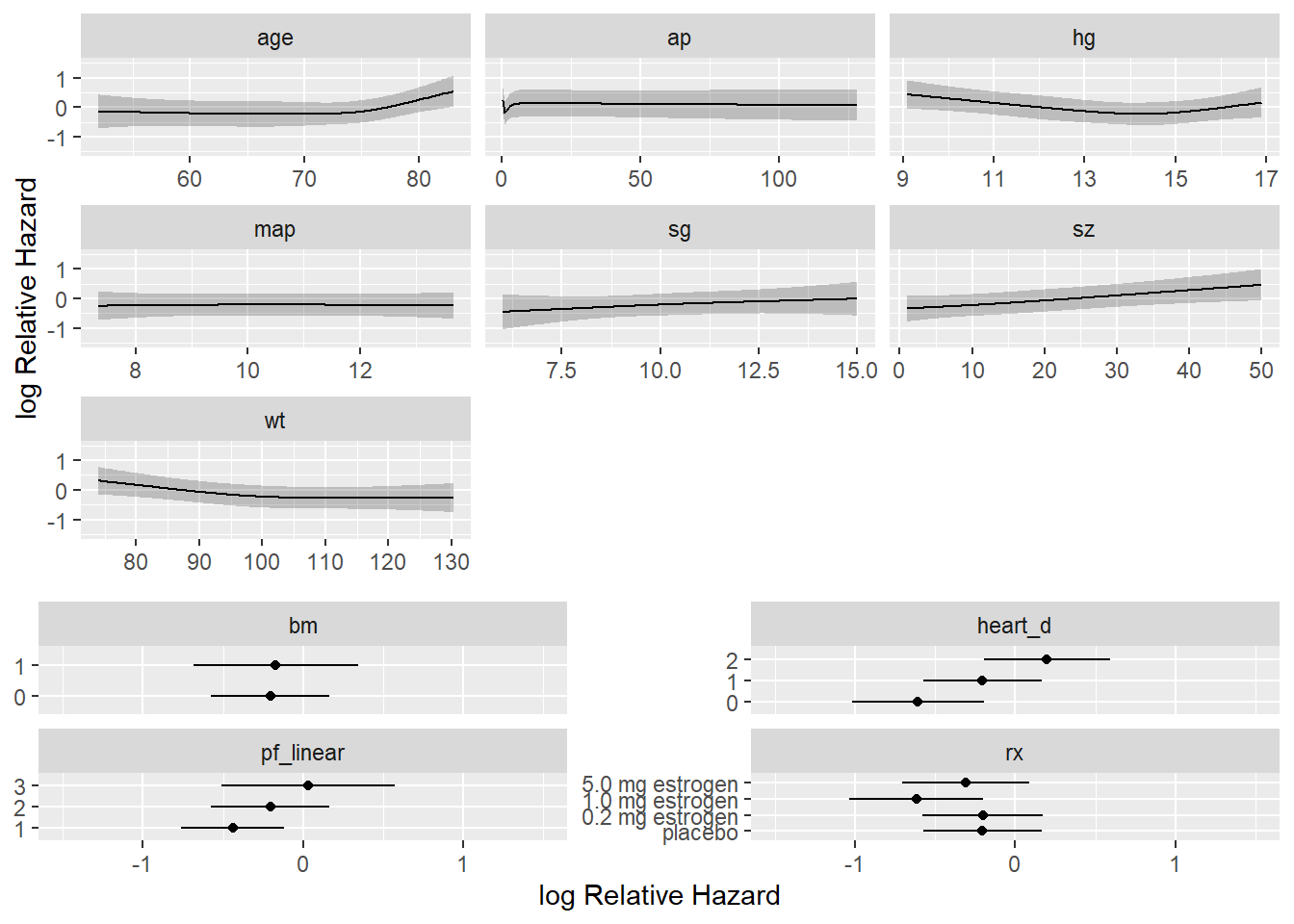
Presenting the final model for inference
To present point and interval estimates of predictor effects we draw a hazard ratio chart. Since the ap relationship is so non-monotonic we use a 20:1 hazard ratio for this variable. The others use the default.
plot(summary(f, ap = c(1, 20)), log = TRUE, main = "")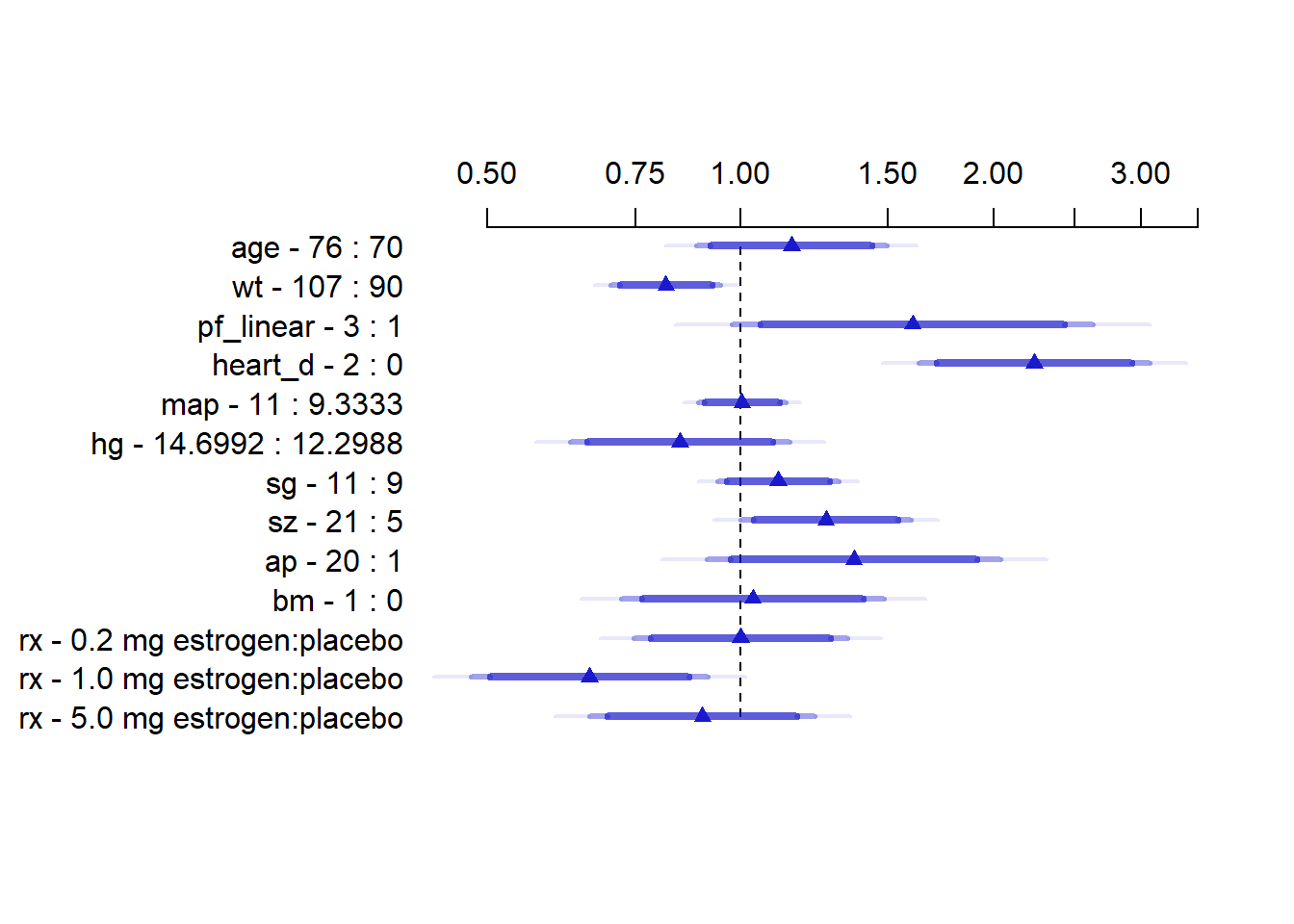
This plot is interpreted as the hazard ratio for each variable if we went from for example age 70 to age 76. \(95\%, 97.5\%\) and \(99\%\) confidence bands are added.
Finally we will also show a nomogram.
surv <- Survival(f)
surv3 <- function(x) surv(3 * 12, lp = x)
surv5 <- function(x) surv(5 * 12, lp = x)
quan <- Quantile(f)
med <- function(x) quan(lp = x) / 12
ss <- c(.05, .1, .2, .3, .4, .5, .6, .7, .8, .9, .95)
nom <- nomogram(f,
ap = c(.1, .5, 1, 2, 3, 4, 5, 10, 20, 30, 40),
fun = list(surv3, surv5, med),
funlabel = c(
"3-year Survival", "5-year Survival",
"Median Survival Time (years)"
),
fun.at = list(ss, ss, c(.5, 1:6))
)
plot(nom, cex.axis = 0.8, cex.var = 0.7, xfrac = .65, lmgp = .35)
This is interpreted by taking a value for each predictor and seeing how many points each value correspond to. Then the total amount of points can be used to find the probability of for example 5-year survival.
Model for prediction
For a prediction model one should validate the model. We start by doing that
Validating the model
We will use bootstrapping for validation. We first validate this model for Somers’ \(D_{xy}\) rank correlation between predicted log hazard and observed survival time, and for slope shrinkage. The bootstrap is used (with 1000 resamples) to penalize for possible overfitting.
v <- validate(f, B = 1000)
options(prType = "html")
v| Index | Original Sample |
Training Sample |
Test Sample |
Optimism | Corrected Index |
Lower | Upper | Successful Resamples |
|---|---|---|---|---|---|---|---|---|
| Dxy | 0.3234 | 0.3507 | 0.299 | 0.0517 | 0.2717 | 0.2127 | 0.3308 | 1000 |
| R2 | 0.2176 | 0.2552 | 0.1822 | 0.0729 | 0.1447 | 0.0766 | 0.2104 | 1000 |
| Slope | 1 | 1 | 0.7875 | 0.2125 | 0.7875 | 0.5908 | 0.9889 | 1000 |
| D | 0.0303 | 0.0366 | 0.0248 | 0.0118 | 0.0185 | 0.0066 | 0.0296 | 1000 |
| U | -5e-04 | -5e-04 | 0.0026 | -0.0031 | 0.0026 | -0.0013 | 0.0105 | 1000 |
| Q | 0.0308 | 0.0371 | 0.0222 | 0.0149 | 0.016 | -0.0026 | 0.0304 | 1000 |
| g | 0.7298 | 0.8128 | 0.6389 | 0.1739 | 0.5559 | 0.3855 | 0.7113 | 1000 |
Here “training” refers to accuracy when evaluated on the bootstrap sample used to fit the model, and “test” refers to the accuracy when this model is applied without modification to the original sample. The apparent \(D_{xy}\) is 0.32, but a better estimate of how well the model will discriminate prognoses in the future is \(D_{xy} = 0.27\). The bootstrap estimate of slope shrinkage is \(0.79\), close to the simple heuristic estimate.
Validate the model for predicting the probability of surviving five years
We will use the non-shrinked estimates to show that this model will have some overfitting consistent with regression to the mean.
cal <- calibrate(f, B = 1000, u = 5 * 12)Using Cox survival estimates at 60 Monthsplot(cal, subtitles = FALSE)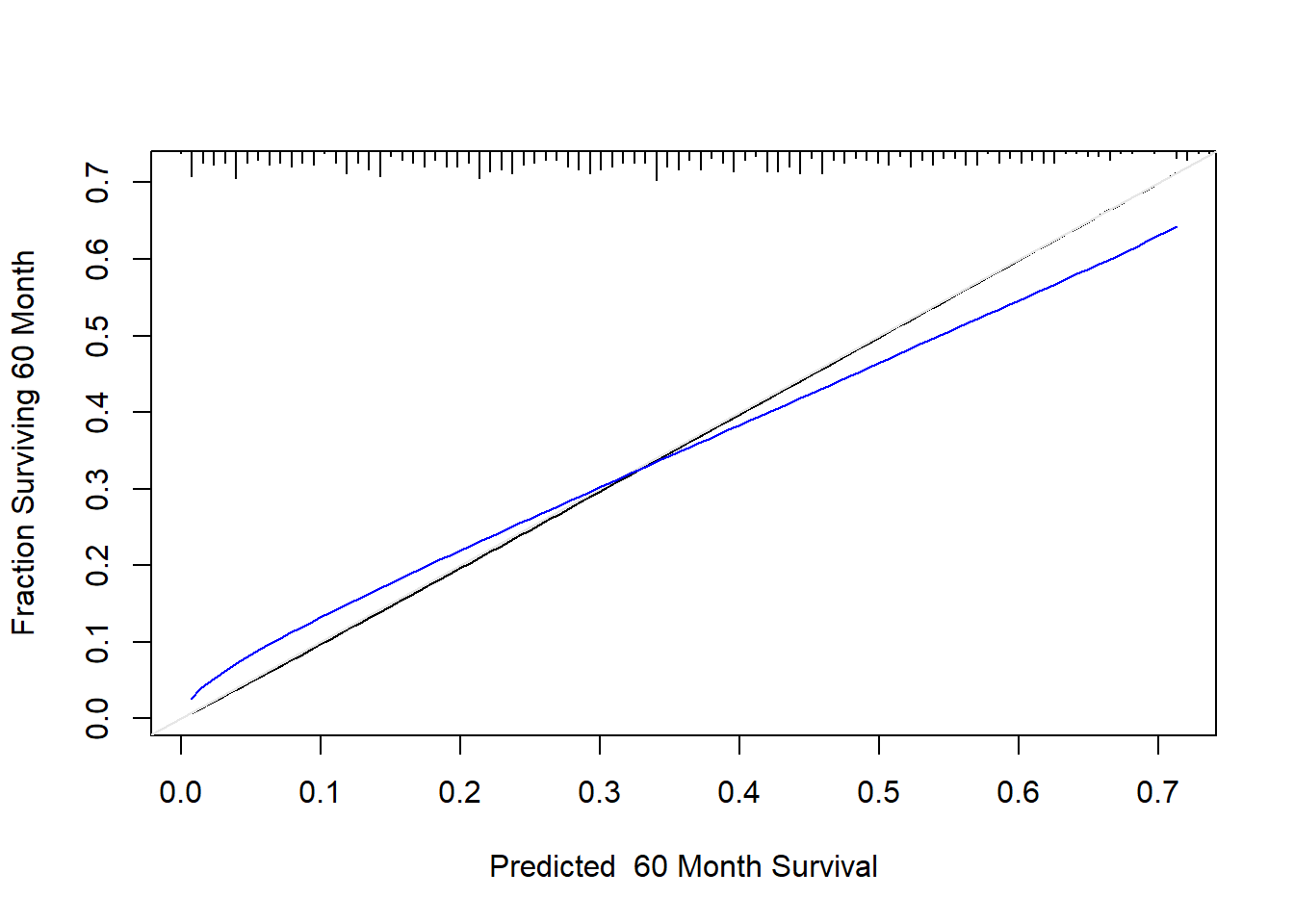
The line nearer the ideal line corresponds to apparent predictive accuracy. The blue curve corresponds to bootstrap-corrected estimates. We clearly see some regression to the mean.
Final model for prediction
For a better model for prediction one should multiply the coefficients in the model by the shrinkage estimate.
v| Index | Original Sample |
Training Sample |
Test Sample |
Optimism | Corrected Index |
Lower | Upper | Successful Resamples |
|---|---|---|---|---|---|---|---|---|
| Dxy | 0.3234 | 0.3507 | 0.299 | 0.0517 | 0.2717 | 0.2127 | 0.3308 | 1000 |
| R2 | 0.2176 | 0.2552 | 0.1822 | 0.0729 | 0.1447 | 0.0766 | 0.2104 | 1000 |
| Slope | 1 | 1 | 0.7875 | 0.2125 | 0.7875 | 0.5908 | 0.9889 | 1000 |
| D | 0.0303 | 0.0366 | 0.0248 | 0.0118 | 0.0185 | 0.0066 | 0.0296 | 1000 |
| U | -5e-04 | -5e-04 | 0.0026 | -0.0031 | 0.0026 | -0.0013 | 0.0105 | 1000 |
| Q | 0.0308 | 0.0371 | 0.0222 | 0.0149 | 0.016 | -0.0026 | 0.0304 | 1000 |
| g | 0.7298 | 0.8128 | 0.6389 | 0.1739 | 0.5559 | 0.3855 | 0.7113 | 1000 |
shrinkage_est <- v[3, 5] # Extract bootstrap estimate of shrinkage
f_prediction <- f
f_prediction$coefficients <- f$coefficients * shrinkage_est
print(f_prediction, html = TRUE, coef = 3)Cox Proportional Hazards Model
cph(formula = s ~ rx + rcs(age, 4) + rcs(wt, 3) + pf_linear +
heart_d + rcs(map, 3) + rcs(hg, 4) + rcs(sg, 3) + rcs(sz,
3) + rcs(log(ap), 5) + bm, data = prostate, x = TRUE, y = TRUE,
surv = TRUE, time.inc = 5 * 12)

| Model Tests | Discrimination Indexes |
|
|---|---|---|
| Obs 483 | LR χ2 118.48 | R2 0.218 |
| Events 344 | d.f. 24 | R224,483 0.178 |
| Center -2.2006 | Pr(>χ2) 0.0000 | R224,344 0.240 |
| Score χ2 125.95 | Dxy 0.323 | |
| Pr(>χ2) 0.0000 |
| β | S.E. | Wald Z | Pr(>|Z|) | |
|---|---|---|---|---|
| rx=0.2 mg estrogen | -0.0103 | 0.1518 | -0.07 | 0.9460 |
| rx=1.0 mg estrogen | -0.3045 | 0.1675 | -1.82 | 0.0690 |
| rx=5.0 mg estrogen | -0.0722 | 0.1595 | -0.45 | 0.6509 |
| … |
Approximating the full model
If the client doesn’t want to collect all these variables for prediction we can do model approximation. The goal is to explain f_predictionwith a trade off between parameters and \(R^2\). This can be done by backwards selection.
z <- predict(f_prediction) # compute linear predictor from full model
# Force sigma to be 1 since perfect fit
a <- ols(z ~ rx + rcs(age, 4) + rcs(wt, 3) + pf_linear + heart_d + rcs(map, 3)
+ rcs(hg, 4) + rcs(sg, 3) + rcs(sz, 3)
+ rcs(log(ap), 5) + bm, sigma = 1, data = prostate)
backwards <- fastbw(a, aics = 10000)
print(backwards, html = TRUE, digits = 3)
Deleted Chi-Sq d.f. P Residual d.f. P AIC R2
map 0.42 2 0.8124 0.42 2 0.8124 -3.58 0.998
bm 0.22 1 0.6428 0.63 3 0.8894 -5.37 0.997
sg 3.40 2 0.1826 4.03 5 0.5449 -5.97 0.980
pf_linear 4.77 1 0.0289 8.81 6 0.1848 -3.19 0.956
rx 12.93 3 0.0048 21.73 9 0.0098 3.73 0.892
age 14.73 3 0.0021 36.46 12 0.0003 12.46 0.819
wt 13.66 2 0.0011 50.12 14 0.0000 22.12 0.751
ap 20.68 4 0.0004 70.80 18 0.0000 34.80 0.648
hg 31.13 3 0.0000 101.93 21 0.0000 59.93 0.493
sz 44.95 2 0.0000 146.88 23 0.0000 100.88 0.269
heart_d 54.02 1 0.0000 200.90 24 0.0000 152.90 0.000
Approximate Estimates after Deleting Factors
Coef S.E. Wald Z P
[1,] 8.96e-11 0.0455 1.97e-09 1
Factors in Final Model
NoneNow the client can choose the trade-off between predictive ability and number of predictors. We visualize this in the following plot
result <- as.data.frame(backwards$result)
total_predictors <- nrow(result)
r_squared <- result$R2
predictors <- c((total_predictors - 1):0)
ggplot(data.frame(predictors, r_squared), aes(x = predictors, y = r_squared)) +
geom_line(color = "blue") +
geom_point(color = "red") +
labs(x = "Predictors", y = TeX("$R^2$")) +
ggtitle("R-squared vs. Predictors") +
scale_y_continuous(breaks = pretty_breaks()) +
theme_minimal()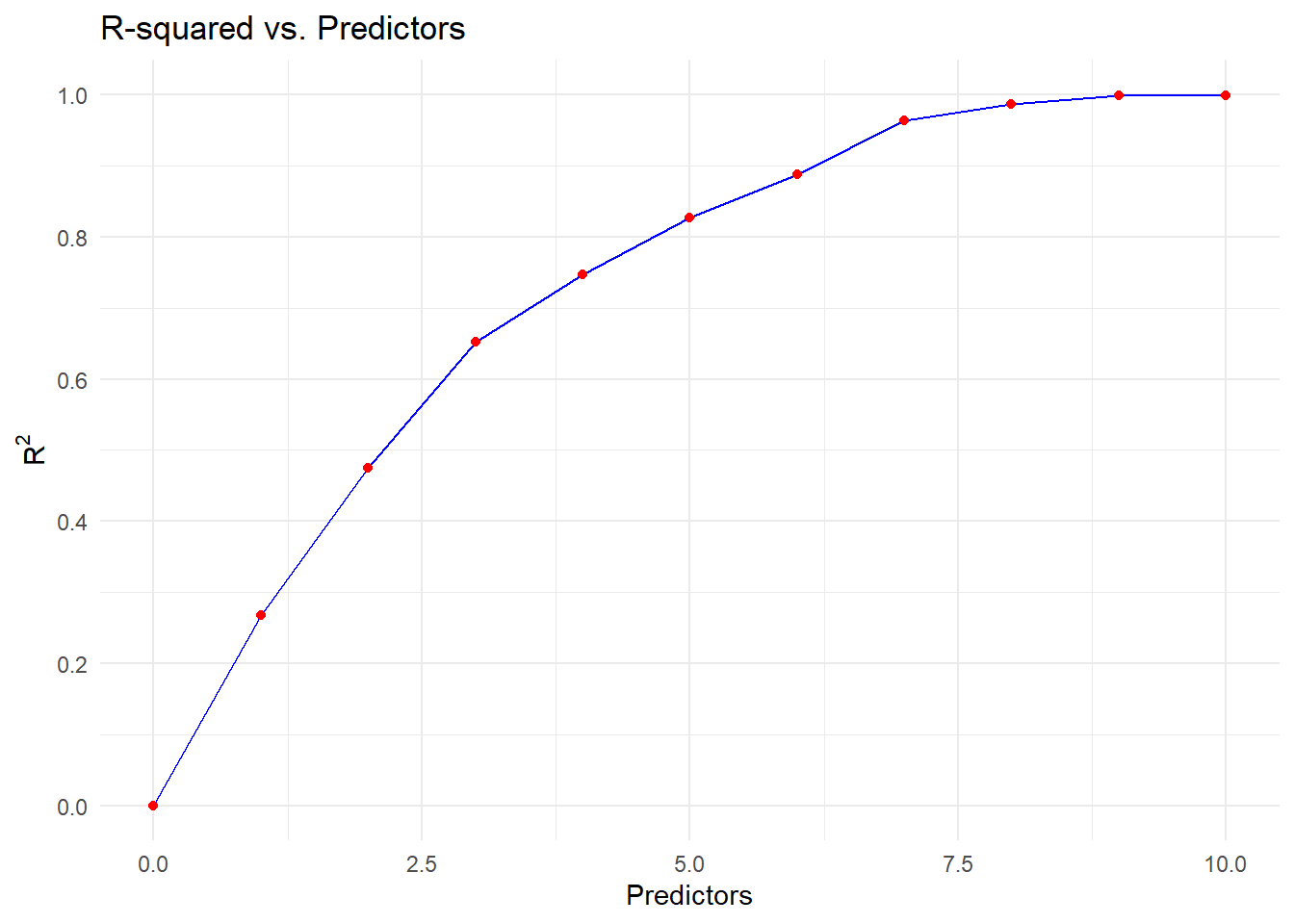
A reasonable approach trade off would be to remove map, bm, sg and pf_linear from our model to get an approximate model which still has high \(R^2\) of \(0.96\) for explaining the full model.
f_approx <- ols(z ~ rx + rcs(age, 4) + rcs(wt, 3) + heart_d
+ rcs(hg, 4) + rcs(sz, 3) + rcs(log(ap), 5)
, x = TRUE, data = prostate)
print(f_approx, html = TRUE, coefs = 3)Linear Regression Model
ols(formula = z ~ rx + rcs(age, 4) + rcs(wt, 3) + heart_d + rcs(hg,
4) + rcs(sz, 3) + rcs(log(ap), 5), data = prostate, x = TRUE)

| Model Likelihood Ratio Test |
Discrimination Indexes |
|
|---|---|---|
| Obs 483 | LR χ2 1510.49 | R2 0.956 |
| σ 0.1378 | d.f. 18 | R2adj 0.954 |
| d.f. 464 | Pr(>χ2) 0.0000 | g 0.715 |
Residuals
Min 1Q Median 3Q Max -0.44623 -0.08724 -0.02054 0.05327 0.63271
| β | S.E. | t | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | 3.9360 | 0.2263 | 17.39 | <0.0001 |
| rx=0.2 mg estrogen | -0.0030 | 0.0178 | -0.17 | 0.8652 |
| rx=1.0 mg estrogen | -0.4058 | 0.0179 | -22.69 | <0.0001 |
| … |
Conclusion
We devolved a Cox proportional hazards model to explain time until death (of any cause) for this dataset. We described the effects the predictors in the model had by various plots.
We did validation and calibration if one wished to use the model for prediction, to avoid issues such as regression to the mean. We then developed a simplified model which dropped 4 predictors, but could still predict the full model with high accuracy (\(R^2=0.964)\).
Throughout we used the guidelines of Regression Modelling Strategies to follow sounds statistical strategies when building and validating a model.